How I solved the Machine Learning Preatorian Challenge
However, do note that if you do solve a challenge, they no longer update their leader board crediting solvers.
The Preatorian Challenges are set up predmonantly as a filter to find job applicants. The gist is to take a look at the six challenges, pick your strength, solve the puzzle with the information, submit your resume, and potentially get a job and be put on their leader board. While they have a nice speech as to their requirements that a person must "expected to demonstrate knowledge, persistence, honor and integrity", not putting solvers on the leaderboard and no longer giving out the hash code given successful processing might not match their requirements. With that aside, the challenges done for their own sake are another thing. For those who love puzzles, and have the skills to attack such problems and solve them, they can be quite irresistable.
IF your interested in solving puzzles and using your super coding powers for the sake of good and society, I would check out some of these sites! See: Google Kaggle Challenges / Innocentive Crowd Sourced Solutions / Quantopian Quant Finance / and many more!
The Setup
The point of the Machine Learning challenge is to demonstrate your ablity to build an Artificial Intelligence classifier solution. There are many kinds of Neural Net frameworks to use (Scala, Pytorch, Tensor Flow, Keras, etc), and many kinds of nets you can work on within them (CNN, RNN, Feedforward, Tabular, Adversarial, etc), there are even pretrained nets and layers one can use as well (one of the most fun being YOLOv2, MaskRCN, etc). Even if you do not have a desktop machine capable of training in a reasonable time, you can use use Googgle Cloud GPUs along with Amazon (AMI Developer Guide) and even others wishing to cash in like Lambda Labs.
Owning a machine capable of doing this kind of learning also helped drive my choice as to which AI and language I would use. My choice was Python a new language (for me) to learn, which requires learning some interesting libraries from the classic Numpy, Matplotlib, and CV2 (used to pre-process visual information), among many others. With a whole lot of effort to install what was needed to develop (Anaconda, Spyder, Jupyter, Visual Studio Code, Docker, Git, etc). There is no sense boring you with those details, suffice it to say it went well, and I was off to the races quickly.
Now that I just climbed the mountain of Python, I also had to climb the AI mountain... From El Capitan, to K2, I really dove into things (as I always do). Deciding what kind of network would fit the problem I went with a Tabular Network and for this decided to use FastAI to help speed up my learning and time to completion.
The Problem
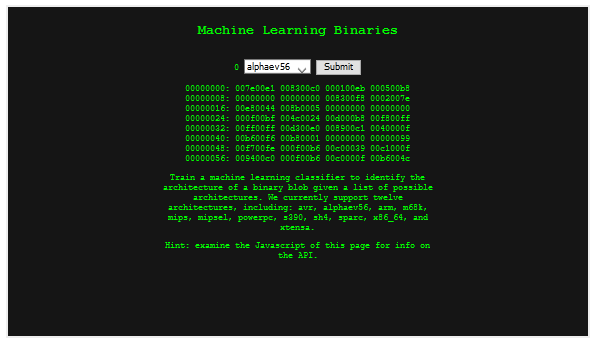
Preatorian, for the machine language challenge provides only a description: Build an AI classifier (or other kind?), and have it determine, by examining 40 blocks of binary,
which of twelve archetectures the code is from. They do not provide a learning set or anything other than a form - and a bit of instruction on interacting with their API.
The first thing one needs to do is gather enough information necessary to train a net, often more information is better. As romatic or exciting it sounds to do AI, most of the actual work is not doing AI. Most of your work will consist of deciding what data is needed to train the network you're going to create, collect it, then put it in a format conducive to the rest of the project. By far, this is what dominates the amount of time in any project in which a pre-made dataset is not provided. Often, even if a dataset IS provided, it has to be processed and ordered and set up for the problem itself or your version of the problem solution.
Getting the Data
In this case all you get is a tiny form, that when you hit submit, sends a guess (random guess that is only right on average 1/12th the time), and then gets a response as to the status (wrong or right), and what the right answer should be. So if the code guesses that its a mips machine, it may say that guess was wrong and inform you that the binary was for a xtensa machine.
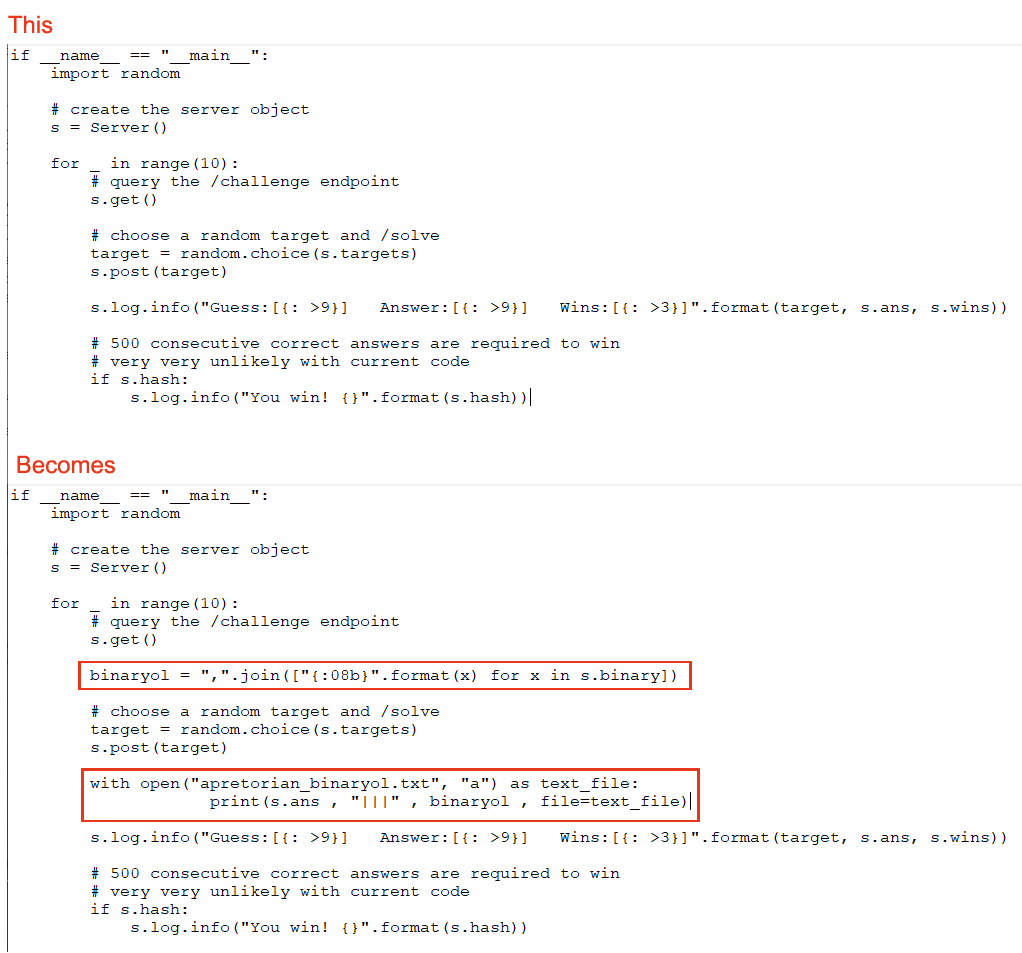
The other change was to change the number of guesses to a large number which would cause the code to go from 10 guesses to 100,000 guesses, storing the data to disk. The final output had to then be filtered so duplicates were removed which can influence the training of the network.
Training the Net
Training a network once the structure is determined is pretty straightforward. In the olden days when dinosaurs walked the earth, one would not only have to write the code (usually in C for speed, or go nuts writing in Assembler), and write all the details of how the net would be trained. Today, things are a lot easier, with Tensor Flow, Pytorch, and FastAI (using pytorch), making this more of a consumption model than a Phd level thesis paper.
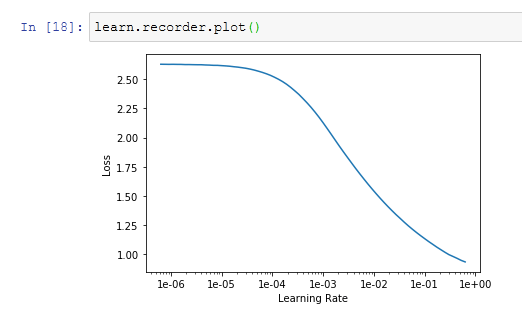
The data gets split up into its respective training and test sets, and the network training process is then started. This is still a kind of "art" rather than a science.
How large the layers are and how many layers there are, are really up to the person doing the network, and so far there isn't a good metric to decide, but I am sure they are working on
it given how much it can influence the outcomes. Lucking out in the fact my intuition picked a good set of structures, the training was quite straightforward.
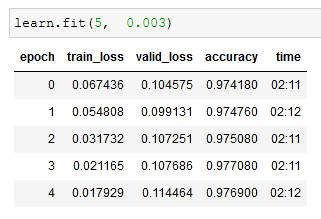
Validation resulted in good outcomes showing how powerful this methodology can be. However it took a bit more training as two of the archetectures were close to each other and were hard to differentiate.
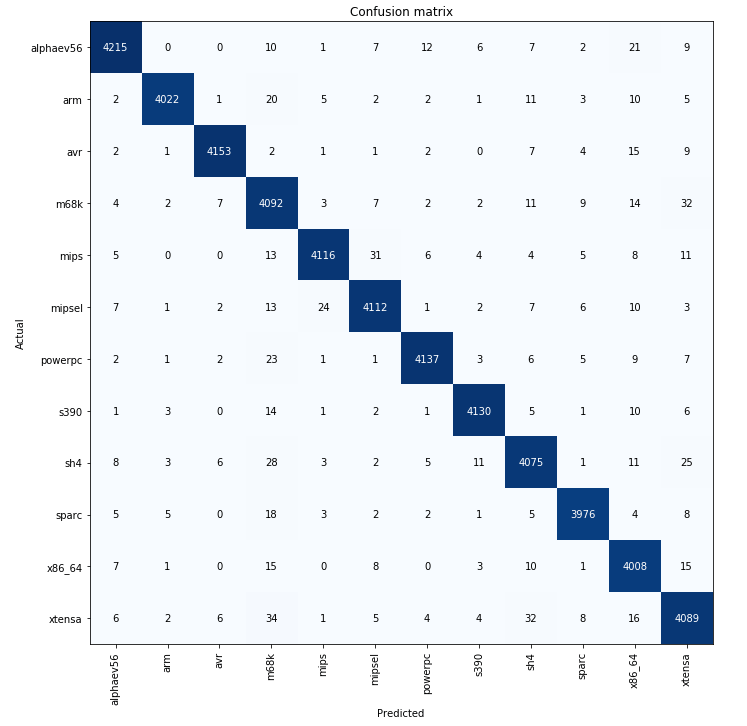
Rounding The Bend
While the above makes it seem that it was one two three easy, there were a lot of fits and starts, and reruns, and even going back to get more data at one point. By now I had moved from spyder editor, to Jupyter notebook, as its ability to allow running python code in pieces and make quick changes was favored. Once the net was sufficiently trained, the next step was to save it as a pickle (pkl) file. After all, the code that was used to structure the training session and validate, is not the code that would be used to process data once finished. So a pkl file was used to save the trained network for use in another location. Actually by the end of this period of training and tweaking I had created 7 pkl files. The network was successful by the fifth generation, but failure to get a hash code had me go back and improve it, trying over and over again.

So it was back to the original form, and change it so that now, instead of making a random guess, it would use the tabular neural net to make its attempts.
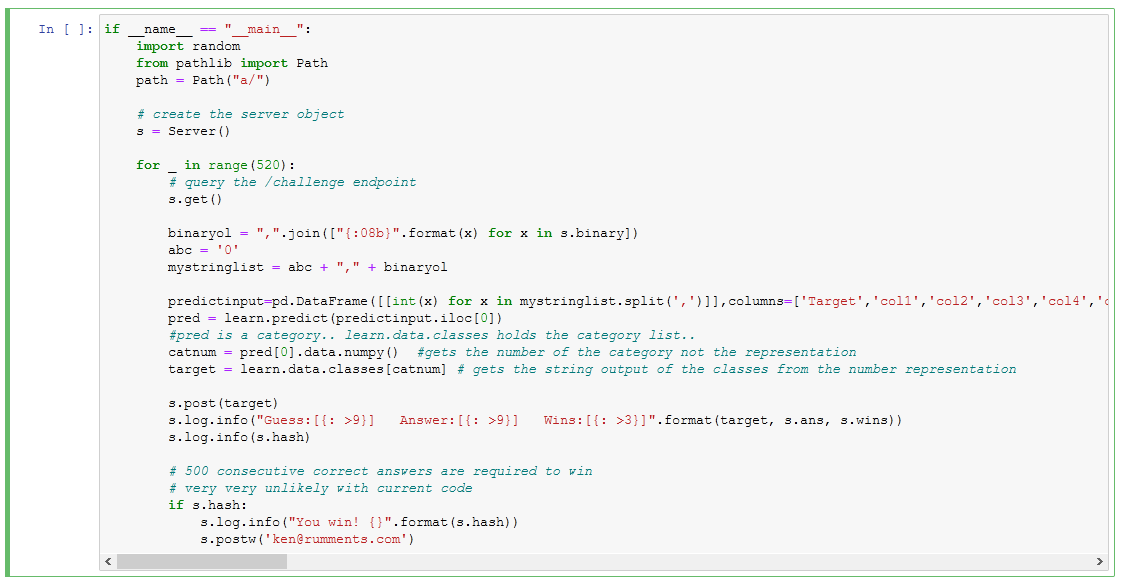
The Final Stretch
The requirements are 500 sequential correct guesses. Something that the random guesses in the original form would be VERY unlikely to accomplish. Once the code was in place, and some tests completed, it was off to the races. The first set as mentioned above succeeded, but gave no hash, even though it hit 500. If one of my tests did, and I missed it, I ran it again, and no hash. I went into the browser, and deleted cookies, and even extended the training of the network some more, increasing the downloaded pool of data to 100,000 records.
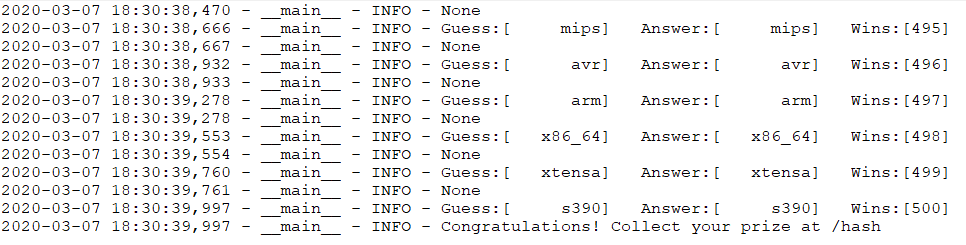
At this point I discovered their server, while contratulating you that you made it, did not give out a confirmation hash any more. Sadly, I put my record together, wrote a cover letter to the HR department, included my resume, and waited. The return message was a bit disheartening in that my 30 years of engineering was not something they thought applied. I inquired about the leaderboard, as that would be a nice consolation prize for all the effort and not getting an interview. They responded that they would forward the issue of the hash to their programming department. They never replied after that and my email was never included on their leaderboard.
I then realized that putting people up on the leader board probably wasn't done any more. Maybe because too many people solve them now? Who knows other than Preatorian. They obviously still keep the challenges up, as they obviously still use it as a way to get resume submissions (though now rather, in my opinion, disingenuous).
So there it is, how the Preatorian Machine Language challenge was met and subdued. While it did not result in the rewards as promised, it was still a great way to quickly learn a new language,
apply it, and even learn how to employ AI into my future applications. Maybe later I will solve or show up as a contender in a Kaggle competition? or maybe an employer would want me to create,
generate, and integrate such into some product or system they have need for? I certainly don't know what the future holds, other than to be sure, I will find more puzzles and challenges to defeat.
